")

Following my latest article “CssSelectors not only for styling” many people asked me about the difference between using CssSelector and XPath, and what are the benefits to using XPath as a locator. Sadly, I see many engineers struggling to identify an element by using other selectors, find themselves blindly copying a WebElement’s XPath using the option provided by the browser. The deal is that the expression received is mostly highly flaky and ugly none the less.
In this article, I’m going to cover this topic and see if we can demystify XPath and make it more accessible.
What is XPath?
XPath stands for XML Path Language. It is basically a Quarry language that was originally made for selecting nodes from an XML document that was defined by the W3C. XPath can be used for XML schemes and also in many programming languages (Such as Java, Python, PHP, and even C).
How is it related to Test Automation?
XPath is one of the 8 locating methods (9 if you count relative locators added in Selenium 4 alpha). to identify elements in the application under test.
By using XPath we can query an element in a more flexible way, locating it by the full or relative path in the document object model and even use some of its internal libraries to compute a specific element by defining several conditions within the expression. XPath is a highly flexible and strong locating method. It allows us to locate elements by a static visible text, elements with no unique properties or even without any attributes at all.
How to use XPath to locate WebElements?
For this part, I’m going to use Chrome Dev Tools to demonstrate some usage examples.
The website I’m using is Google.com’s main search page.
Understanding the syntax
Full path to a WebElement:
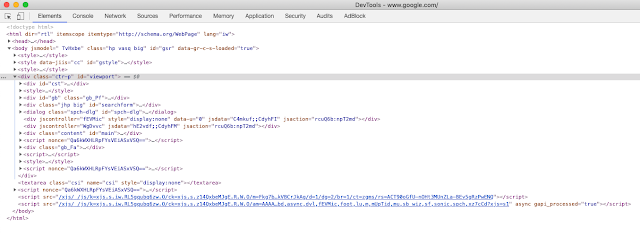
Let’s say I want to query the first div on this webpage using its full path in the DOM which is:
/html/body/div
What does this expression mean?
Within the <html> tag, find the <body> tag, in the body tag, select the first <div> tag you find. And that will be my target element.
Relative path
In most cases using a relative path would be preferred. Why?
Let’s look at a more complex example. Let’s say that I want to identify the search text field.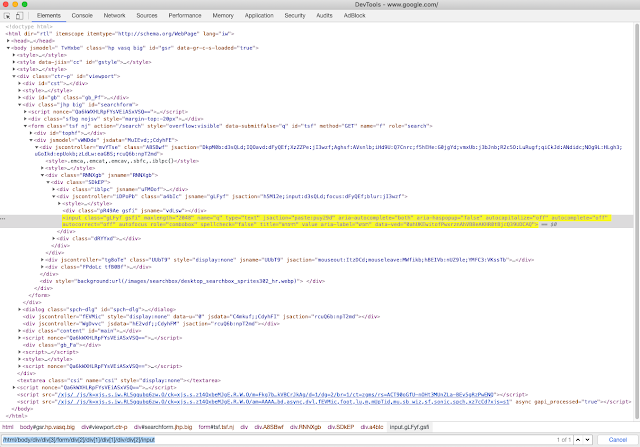
This is the expression I would need:
/html/body/div/div[3]/form/div[2]/div[1]/div[1]/div/div[2]/input
In the <html> tag look for the <body> tag, find the first <div>, in which look for the third <div>, find the <form> tag in it, look for the third <div> in that tag… well, you get the point.
If even one of the “Stops” leading to my target in this expression “Breaks”, the expression will no longer lead to the desired element.
Basically, I can identify the same element by using a shorter expression such as:
//input[4]
Which means, the third input tag in the DOM
or a stronger one:
//input[@type=”text”]
Which means the first input tag with a type “text” you find. In our case it would be unique.
Locating by static visible text
Let’s say that we want to locate this text:
![]()
Well, It has an ID but if it didn’t I could choose to locate it via its static text with the following XPath syntax:
//div[text()=’Google זמינה ב: ‘]
But, what if only a part of the text is static?
Well, in that case, I could choose to find it with the “contains” keyword.
//div[contains(text(),’Google’)]
or:
//div[starts-with(text(),’Google’)]
What about an element’s parent?
I can use the same expression to locate that element’s parent. Fo example:
//div[@id=’SIvCob’]/parent::div
What if I want to find all elements on a page containing a particular text?
I can use Wildcards to find this element without specifying a particular tag
//*[contains(text(),’Google’)]
Locating elements by providing multiple attributes
If needed, we can use multiple attribute selection in our XPath syntax. For example, I can locate the Search button by both name and type:
//input[@class=’gNO89b’] [@type=’submit’]
In conclusion:
Both CSS and XPath are highly powerful locating strategies. Depending on the use case you can benefit each of them as they provide you with great flexibility. XPath can navigate up the DOM while CSS cannot (As far as I know) and some say that at least in IE CSS is much faster.
By the way, there are websites such as cssify that help you convert your XPath expression to a CSS selector.
Author bio:
Daniel is the Head of QA & Automation at Testim.io, Blogger, Instructor and International Speaker.
Daniel has worked in various roles which included founding QA and test automation departments from scratch. In his current role Daniel and his team are shaping how the next generation of AI assisted tools help us approach test automation in the future.


